
扫码下载
扫码下载
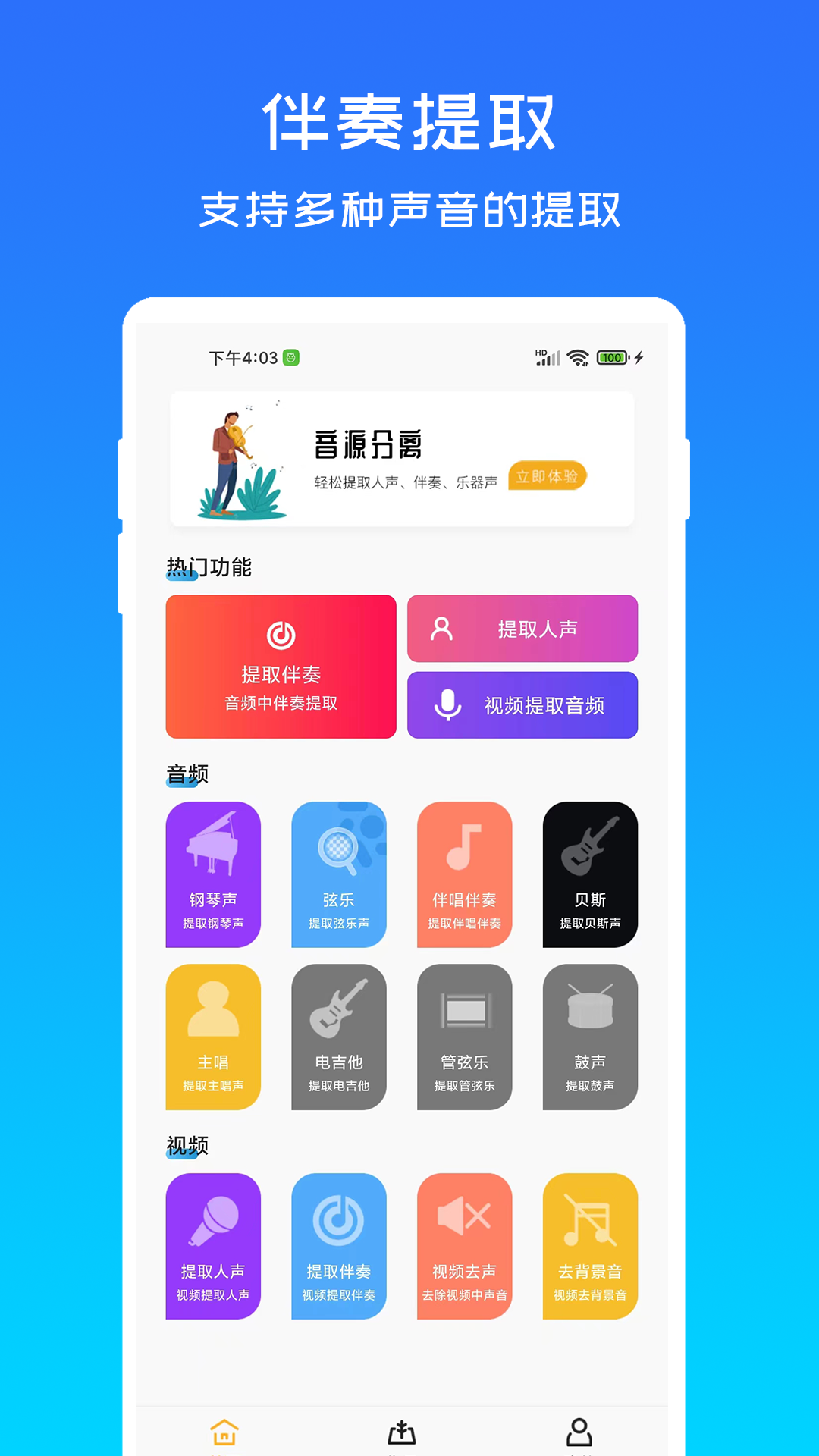
音源分离是一款专注于音频处理的专业级软件,帮助用户从一段完整的音频文件中提取出不同的音轨元素,如人声、乐器、背景噪音等。该软件采用先进的AI算法和深度学习技术,能够精准识别并分离出音频中的多层声音结构,广泛适用于音乐制作人、音频工程师、剪辑师以及普通音乐爱好者。其操作界面简洁直观,功能逻辑清晰,兼顾了专业用户与初学者的使用需求。
软件介绍
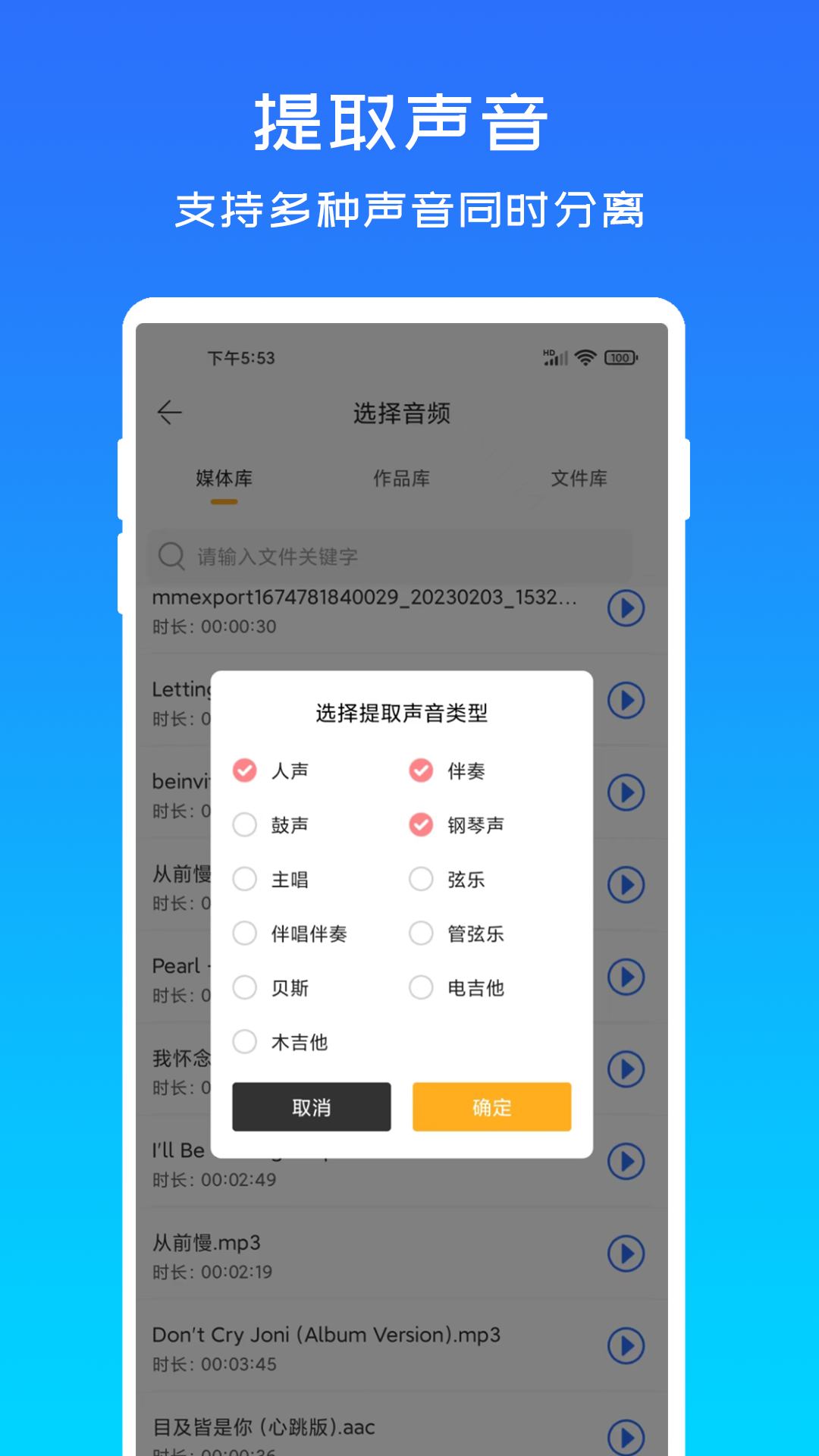
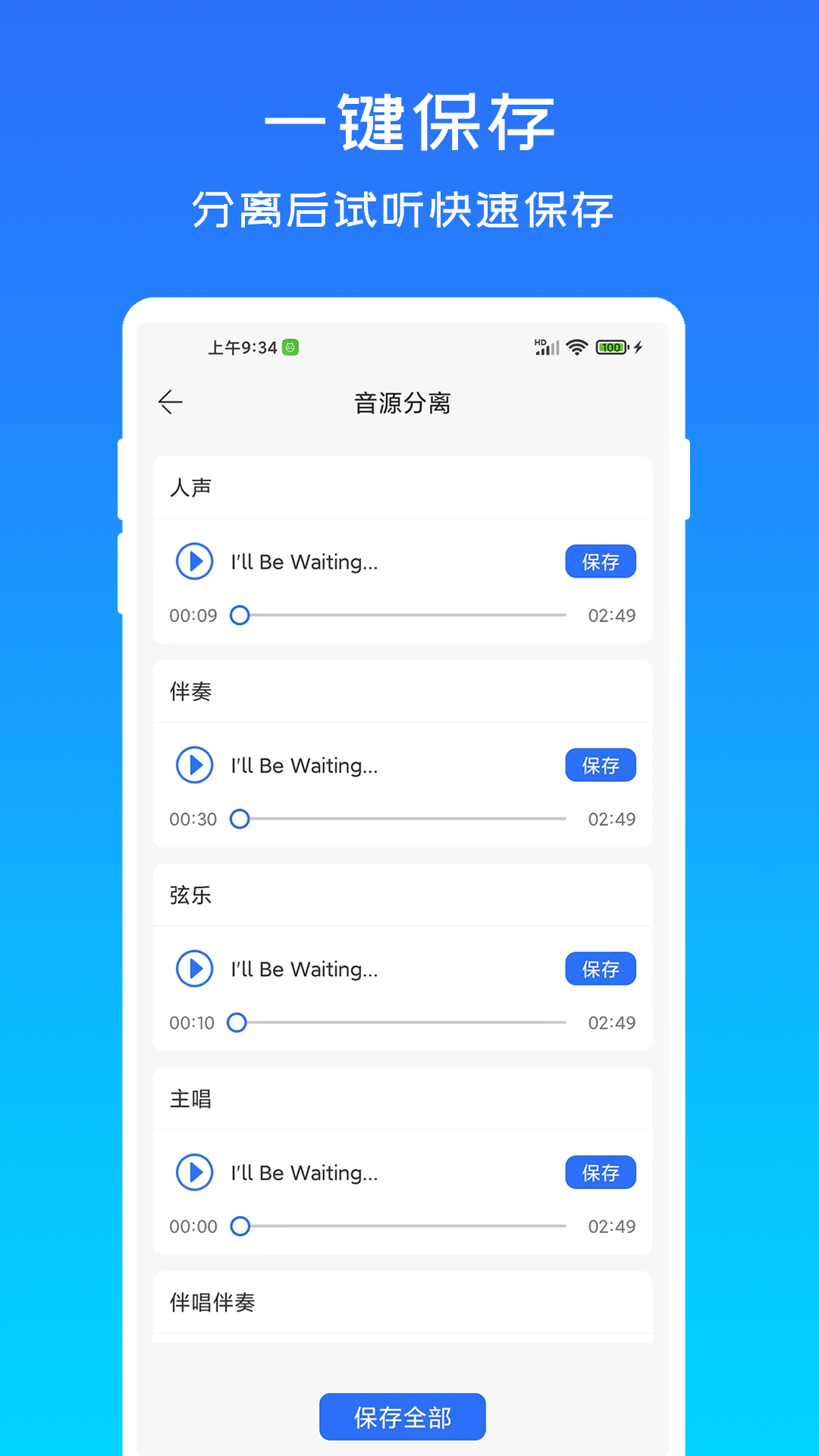
这款软件基于现代神经网络模型开发,能够在不损失音质的前提下,实现高效的音源拆解。用户只需上传音频文件,系统即可自动分析音频结构并生成多个独立音轨。支持多种常见音频格式导入,如MP3、WAV、FLAC等,并可导出为高质量的无损音频文件。软件还内置了多种预设模式,根据不同音频类型进行优化处理,例如人声增强、乐器识别、环境音过滤等,满足多样化使用场景。
软件亮点
软件的最大亮点在于其出色的分离精度与处理速度。在处理复杂混音时,依旧能够保持各音轨之间的清晰度与独立性,避免出现声音干扰或混杂的情况。软件对硬件资源的占用控制得当,即使在配置一般的设备上也能流畅运行。它还支持批量处理功能,可同时处理多个音频文件,大幅提升工作效率,尤其适合需要进行大量音频整理和编辑的用户。
软件特色
除了核心的音源分离功能外,该软件还提供了一系列实用的辅助工具。用户可以在分离后的音轨中进行音量调节、频段分析、混响处理等二次编辑操作。界面设计上采用模块化布局,功能区域划分明确,用户可根据自身需求自由调整工作流程。软件还支持与主流数字音频工作站(DAW)进行无缝对接,便于后续音频编辑与混音工作的开展。
软件优势
首先是技术层面,基于深度学习模型的算法,使得分离效果更加自然真实,适应性强。其次是使用体验方面,软件在操作设计上充分考虑了用户的实际需求,功能调用便捷,响应迅速,学习成本较低。软件提供多语言支持,覆盖全球范围内的用户群体。其更新维护机制完善,开发团队持续优化算法和修复潜在问题,确保软件长期稳定运行。
软件点评
作为一款专业的音频处理工具,该软件在业内获得了广泛的认可。尤其是在处理高密度混音时表现尤为出色。对于音乐创作者来说,它为重新混音、采样提取提供了极大便利;对于内容创作者而言,则有助于快速提取干净的人声用于后期制作。虽然在处理极低质量音频时可能存在一定局限,但其性能和实用性已经达到了行业领先水平,是音频处理领域中值得信赖的工具之一。






















-
如何在少年三国志二中使用军师玩法
07-05
-
英雄联盟手游闪现放在哪儿比较好用
07-10
-
想了解一下影之刃3疯狂医师的解锁方式
06-14
-
有什么方法可以获得摩尔庄园小秋
04-25
-
光遇圣诞桌子的装饰可以用哪些材料
05-08
-
诛仙手游青云加点调整后会有哪些提升
07-13
-
请问摩尔庄园建禽社的步骤是什么
06-05